In what I hope will become a long-running serial, today we will discuss how you can prevaricate, dissemble, equivocate, and in general become as slippery as an eel slathered with axle grease, yet still maintain your mediocre, ill-deserved, but unblemished reputation, without feeling like a repulsive stain on the undergarments of the universe.
I am, of course, talking about making stuff up.
As the human imagination is one of the most wonderful and powerful aspects of our nature, there is no reason you should not exercise it to the best of your ability; and there is no greater opportunity to use this faculty than when the stakes are dire, the potential losses abysmally, wretchedly low, the potential gains dizzyingly, intoxicatingly high. (To get yourself in the right frame of mind, I recommend Dostoyevsky's novella The Gambler.) And I can think of no greater stakes than in reporting scientific data, when entire grants can turn on just one analysis, one result, one number. Every person, at one time or another, has been tempted to cheat and swindle their way to fortune; and as all are equally disposed to sin, all are equally guilty.
In order to earn your fortune, therefore, and to elicit the admiration, envy, and insensate jealousy of your colleagues, I humbly suggest using none other than the lowly correlation. Taught in every introductory statistics class, a correlation is simply a quantitative description of the association between two variables; it can range between -1 and +1; and the farther away from zero, the stronger the correlation, while the closer to zero, the weaker the correlation. However, the beauty of correlation is that one number - just one! - has the inordinate ability to make the correlation significant or not significant.Take, for example, the correlation between shoe size and IQ. Most would intuit that there is no relationship between the two, and that having a larger shoe size should neither be associated with a higher IQ or a lower IQ. However, if Bozo the Clown is included in your sample - a man with a gigantic shoe size, and who happens to also be a comedic genius - then your correlation could be spuriously driven upward by this one observation.
To illustrate just how easy this is, a recently created web applet provides you with fourteen randomly generated numbers, and allows the user to plot an additional point anywhere on the graph. As you will soon learn, it is simple to place the observation in a reasonable and semi-random location, and get the result that you want:
The beauty of this approach lies in its simplicity: We are only altering one number, after all, and this hardly approaches the enormity of scientific fraud perpetrated on far grander scales. It is easy, efficient, and fiendishly inconspicuous, and should anyone's suspicions be aroused, that one number can simply be dismissed as a clerical error, fat-finger typing, or simply chalked up to plain carelessness. In any case, it requires a minimum of effort, promises a maximum of return, and allows you to cover your tracks like the vulpine, versatile genius that you are.
And should your conscience, in your most private moments, ever raise objection to your spineless behavior, merely repeat this mantra to smother it: Others have done worse.
I am, of course, talking about making stuff up.
As the human imagination is one of the most wonderful and powerful aspects of our nature, there is no reason you should not exercise it to the best of your ability; and there is no greater opportunity to use this faculty than when the stakes are dire, the potential losses abysmally, wretchedly low, the potential gains dizzyingly, intoxicatingly high. (To get yourself in the right frame of mind, I recommend Dostoyevsky's novella The Gambler.) And I can think of no greater stakes than in reporting scientific data, when entire grants can turn on just one analysis, one result, one number. Every person, at one time or another, has been tempted to cheat and swindle their way to fortune; and as all are equally disposed to sin, all are equally guilty.
In order to earn your fortune, therefore, and to elicit the admiration, envy, and insensate jealousy of your colleagues, I humbly suggest using none other than the lowly correlation. Taught in every introductory statistics class, a correlation is simply a quantitative description of the association between two variables; it can range between -1 and +1; and the farther away from zero, the stronger the correlation, while the closer to zero, the weaker the correlation. However, the beauty of correlation is that one number - just one! - has the inordinate ability to make the correlation significant or not significant.Take, for example, the correlation between shoe size and IQ. Most would intuit that there is no relationship between the two, and that having a larger shoe size should neither be associated with a higher IQ or a lower IQ. However, if Bozo the Clown is included in your sample - a man with a gigantic shoe size, and who happens to also be a comedic genius - then your correlation could be spuriously driven upward by this one observation.
To illustrate just how easy this is, a recently created web applet provides you with fourteen randomly generated numbers, and allows the user to plot an additional point anywhere on the graph. As you will soon learn, it is simple to place the observation in a reasonable and semi-random location, and get the result that you want:
 |
| Non-significant correlation, leading to despair, despond, and death. |
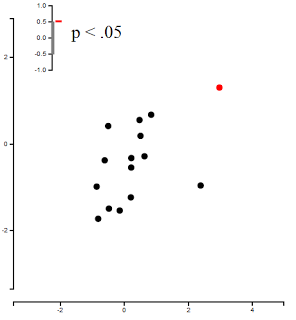 |
| Significant correlation, leading to elation, ebullience, and aphrodisia. |
The beauty of this approach lies in its simplicity: We are only altering one number, after all, and this hardly approaches the enormity of scientific fraud perpetrated on far grander scales. It is easy, efficient, and fiendishly inconspicuous, and should anyone's suspicions be aroused, that one number can simply be dismissed as a clerical error, fat-finger typing, or simply chalked up to plain carelessness. In any case, it requires a minimum of effort, promises a maximum of return, and allows you to cover your tracks like the vulpine, versatile genius that you are.
And should your conscience, in your most private moments, ever raise objection to your spineless behavior, merely repeat this mantra to smother it: Others have done worse.