Clustering, or finding subgroups of data, is an important technique in biostatistics, sociology, neuroscience, and dowsing, allowing one to condense what would be a series of complex interaction terms into a straightforward visualization of which observations tend to cluster together. The following graph, taken from the online Introduction to Statistical Learning in R (ISLR), shows this in a two-dimensional space with a random scattering of observations:
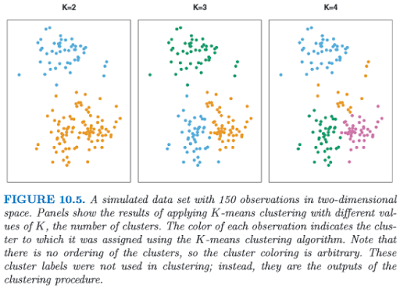
Different colors denote different groups, and the number of groups can be decided by the researcher before performing the k-means clustering algorithm. To visualize how these groups are being formed, imagine an "X" being drawn in the center of mass of each cluster; also known as a centroid, this can be thought of as exerting a gravitational pull on nearby data points - those closer to that centroid will "belong" to that cluster, while other data points will be classified as belonging to the other clusters they are closer to.
This can be applied to FMRI data, where several different columns of data extracted from an ROI, representing different regressors, can be assigned to different categories. If, for example, we are looking for only two distinct clusters and we have several different regressors, then a voxel showing high values for half of the regressors but low values for the other regressors may be assigned to cluster 1, while a voxel showing the opposite pattern would be assigned to cluster 2. The label itself is arbitrary, and is interpreted by the researcher.
To do this in Matlab, all you need is a matrix with data values from your regressors extracted from an ROI (or the whole brain, if you want to expand your search). This is then fed into the kmeans function, which takes as arguments the matrix and the number of clusters you wish to partition it into; for example, kmeans(your_matrix, 3).
This will return a vector of numbers classifying a particular row (i.e., a voxel) as belonging to one of the specified clusters. This vector can then be prefixed to a matrix of the x-, y-, and z-coordinates of your search space, and then written into an image for visualizing the results.
There are a couple of scripts to help out with this: One, createBlankNIFTI.m, which will erase a standardized space image (I suggest a mask output by SPM at its second level) and replace every voxel with zeros, and the other script, createNIFTI.m, will fill in those voxels with your cluster numbers. You should see something like the following (here, I am visualizing it in the AFNI viewer, since it automatically colors in different numbers):
The functions are pasted below, as well as a couple of explanatory videos.
=================================
Different colors denote different groups, and the number of groups can be decided by the researcher before performing the k-means clustering algorithm. To visualize how these groups are being formed, imagine an "X" being drawn in the center of mass of each cluster; also known as a centroid, this can be thought of as exerting a gravitational pull on nearby data points - those closer to that centroid will "belong" to that cluster, while other data points will be classified as belonging to the other clusters they are closer to.
This can be applied to FMRI data, where several different columns of data extracted from an ROI, representing different regressors, can be assigned to different categories. If, for example, we are looking for only two distinct clusters and we have several different regressors, then a voxel showing high values for half of the regressors but low values for the other regressors may be assigned to cluster 1, while a voxel showing the opposite pattern would be assigned to cluster 2. The label itself is arbitrary, and is interpreted by the researcher.
To do this in Matlab, all you need is a matrix with data values from your regressors extracted from an ROI (or the whole brain, if you want to expand your search). This is then fed into the kmeans function, which takes as arguments the matrix and the number of clusters you wish to partition it into; for example, kmeans(your_matrix, 3).
This will return a vector of numbers classifying a particular row (i.e., a voxel) as belonging to one of the specified clusters. This vector can then be prefixed to a matrix of the x-, y-, and z-coordinates of your search space, and then written into an image for visualizing the results.
There are a couple of scripts to help out with this: One, createBlankNIFTI.m, which will erase a standardized space image (I suggest a mask output by SPM at its second level) and replace every voxel with zeros, and the other script, createNIFTI.m, will fill in those voxels with your cluster numbers. You should see something like the following (here, I am visualizing it in the AFNI viewer, since it automatically colors in different numbers):
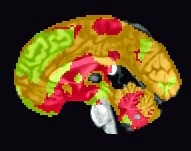 |
| Sample k-means analysis with k=3 clusters. |
The functions are pasted below, as well as a couple of explanatory videos.
function createBlankNIFTI(imageFile) %Note: Make sure that the image is a copy, and retain the original X = spm_read_vols(spm_vol(imageFile)); X(:,:,:) = 0; spm_write_vol(spm_vol(imageFile), X);
=================================
function createNIFTI(imageFile, textFile)
hdr = spm_vol(imageFile);
img = spm_read_vols(hdr);
fid = fopen(textFile);
nrows = numel(cell2mat(textscan(fid,'%1c%*[^\n]')));
fclose(fid);
fid = 0;
for i = 1:nrows
if fid == 0
fid = fopen(textFile);
end
Z = fscanf(fid, '%g', 4);
img(Z(2), Z(3), Z(4)) = Z(1);
spm_write_vol(hdr, img);
end