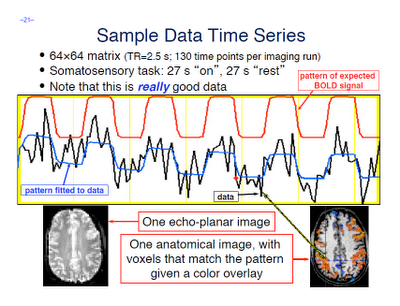
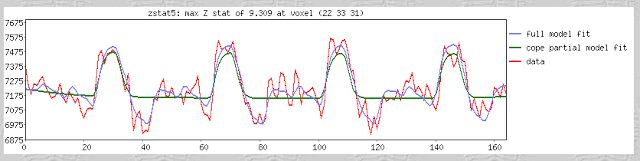
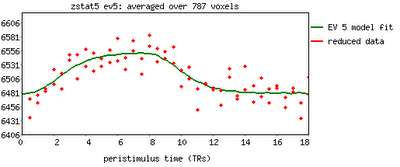
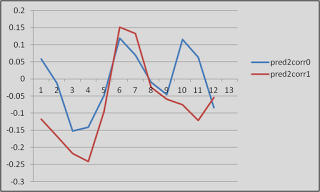
After finishing that cycle of tutorials, I feel as though a summary would be useful. Some of these are points that were highlighted during the walkthroughs, whereas others are germane to any neuroimaging experiment and not necessarily specific to any software analysis package. The past couple of weeks have only scratched the surface as to the many different experimental approaches and analysis techniques that are available, and the number of ways to gather and interpret a set of data are nearly inexhaustible.
That being said, here are some of the main points of FSL:
1) These guys really, really like acronyms. If this pisses you off, if you find it more distracting than useful, I'm sorry.
2) Download a conversion package such as dcm2nii (part of Chris Rorden's mricron package here) in order to convert your data into nifti format. Experiment with the different suffix options in order to generate images that are interpretable and easy to read.
3) Use BET to skull strip your anatomicals as your first step. There is an option for using BET within the FEAT interface; however, this is for your functional images, not your anatomical scans. Skull stripping is necessary for more accurate coregistration and normalization, or warping your images to a standardized space.
4) As opposed to other analysis packages, FSL considers each individual run to be a first-level analysis; an individual subject comprising several runs to be a second-level analysis; collapsing across subjects to be a third-level analysis; and so forth. I recommend using the FEAT interface to produce a template for how you will analyze each run (and, later, each subject), before proceeding to batch your analyses. Especially for the beginner, using a graphical interface is instructive and helps you to comprehend how each step relates to the next step in the processing stream; however, once you feel as though you understand enough about the interface, wean yourself off it immediately and proceed to scripting your analyses.
5) Use the Custom 3-column option within the Stats tab of FEAT in order to set up your analysis. Most studies these days are event-related, meaning that events are of relatively short duration, and that the order of presentation is (usually) randomized. Even if your analysis follows the same pattern for each run, it is still a good habit to use and get comfortable with entering in 3-column timing files for your analysis.
6) If your initial attempts at registration and normalization fail, set the coregistration and normalization parameters to full search and maximum degrees of freedom (i.e., 12 DOF). This takes more time, but has fixed every registration problem I have had with FSL.
7) Look at the output from your stats, and make sure they are reasonable. If you have done a robust contrast which should produce reliable activations - such as left button presses minus right button presses - make sure that it is there. If not, this suggests a problem with your timing, or with your images, which is a good thing to catch early. Also look at your design matrix, and make sure that events are lined up when you think they should be lined up; any odd-looking convolutions should be investigated and taken care of.
8) This piece of advice was not covered in the tutorials, nor does it apply to neuroimaging analysis itself exactly, but it bears repeating: Run a behavioral experiment before you scan. Obtaining behavioral effects - such as reaction time differences - are good indicators that there may actually be something going on neurally that is causing the observed effects. The strength and direction of these behavioral differences will allow you to predict and refine your hypotheses about where you might observe activation, and why. Furthermore, behavioral experiments are much cheaper to do than neuroimaging experiments, and can lead to you to make considerable revisions to your experimental paradigm. Running yourself through the experiment will allow you to make a series of commonsense but important judgments, such as: Do I understand how to do this task? Is it too long or too boring, or not long enough? Do I have any subjective feeling about what I think this experiment should elicit? It may drive you insane to pilot your study on yourself each time you make a revision, but good practice, and can save you much time and hassle later.
That's about it. Again, this is targeted mainly toward beginners and students who have only recently entered the field. All I can advise is that you stick with it, take note of how the top scientists run their experiments, and learn how to script your analyses as soon as possible. It can be a pain in the ass to learn, especially if you are new to programming languages, but it will ultimately save you a lot of time. Good luck.
That being said, here are some of the main points of FSL:
1) These guys really, really like acronyms. If this pisses you off, if you find it more distracting than useful, I'm sorry.
2) Download a conversion package such as dcm2nii (part of Chris Rorden's mricron package here) in order to convert your data into nifti format. Experiment with the different suffix options in order to generate images that are interpretable and easy to read.
3) Use BET to skull strip your anatomicals as your first step. There is an option for using BET within the FEAT interface; however, this is for your functional images, not your anatomical scans. Skull stripping is necessary for more accurate coregistration and normalization, or warping your images to a standardized space.
4) As opposed to other analysis packages, FSL considers each individual run to be a first-level analysis; an individual subject comprising several runs to be a second-level analysis; collapsing across subjects to be a third-level analysis; and so forth. I recommend using the FEAT interface to produce a template for how you will analyze each run (and, later, each subject), before proceeding to batch your analyses. Especially for the beginner, using a graphical interface is instructive and helps you to comprehend how each step relates to the next step in the processing stream; however, once you feel as though you understand enough about the interface, wean yourself off it immediately and proceed to scripting your analyses.
5) Use the Custom 3-column option within the Stats tab of FEAT in order to set up your analysis. Most studies these days are event-related, meaning that events are of relatively short duration, and that the order of presentation is (usually) randomized. Even if your analysis follows the same pattern for each run, it is still a good habit to use and get comfortable with entering in 3-column timing files for your analysis.
6) If your initial attempts at registration and normalization fail, set the coregistration and normalization parameters to full search and maximum degrees of freedom (i.e., 12 DOF). This takes more time, but has fixed every registration problem I have had with FSL.
7) Look at the output from your stats, and make sure they are reasonable. If you have done a robust contrast which should produce reliable activations - such as left button presses minus right button presses - make sure that it is there. If not, this suggests a problem with your timing, or with your images, which is a good thing to catch early. Also look at your design matrix, and make sure that events are lined up when you think they should be lined up; any odd-looking convolutions should be investigated and taken care of.
8) This piece of advice was not covered in the tutorials, nor does it apply to neuroimaging analysis itself exactly, but it bears repeating: Run a behavioral experiment before you scan. Obtaining behavioral effects - such as reaction time differences - are good indicators that there may actually be something going on neurally that is causing the observed effects. The strength and direction of these behavioral differences will allow you to predict and refine your hypotheses about where you might observe activation, and why. Furthermore, behavioral experiments are much cheaper to do than neuroimaging experiments, and can lead to you to make considerable revisions to your experimental paradigm. Running yourself through the experiment will allow you to make a series of commonsense but important judgments, such as: Do I understand how to do this task? Is it too long or too boring, or not long enough? Do I have any subjective feeling about what I think this experiment should elicit? It may drive you insane to pilot your study on yourself each time you make a revision, but good practice, and can save you much time and hassle later.
That's about it. Again, this is targeted mainly toward beginners and students who have only recently entered the field. All I can advise is that you stick with it, take note of how the top scientists run their experiments, and learn how to script your analyses as soon as possible. It can be a pain in the ass to learn, especially if you are new to programming languages, but it will ultimately save you a lot of time. Good luck.